
Herhangi bir programlama dili kullanarak, soket ya da benzeri bir haberleşme protokolü kullandıysanız, eninde sonunda “checksum” kavramı ile karşılaşmışsınızdır. Nedir peki “checksum”?
Türkçe karşılığı “sağlama toplamı” olarak ifade edebileceğimiz “checksum”, herhangi bir şekilde iletilen ya da saklanan verinin, özel fonksiyon ya da algoritmalar kullanılarak, elde edilen daha küçük boyutlu veriye verilen isimdir. Bu veri, temel olarak, iletilen ya da saklanan verinin bütünlüğünü kontrol etmek için kullanılır. Aşağıda bu kullanıma ilişkin bir çizim görebilirsiniz. Bu değerler, “hash” olarak da nitelendirilebiliyorlar.

Amaç, kısıtlar ve diğer benzeri koşullar ışığında kullanabileceğiniz bir çok “checksum” ya da “hash” algoritması bulunmaktadır. Bunlardan bir kısmına örnek: MD5, SHA-1, SHA-256 ve SHA-512’dır.
Bu algoritmalara ilişkin bir diğer önemli husus da, genelde bunlara sabit bir boyut ayrılması ve ilgili veri ne kadar büyük olursa olsun bu alanın değişmemesi, fakat ilgili “checksum” ya da “hash” değerinin çok farklı olabilmesidir. Elbette bu kullanılacak olan yönteme de bağlıdır.
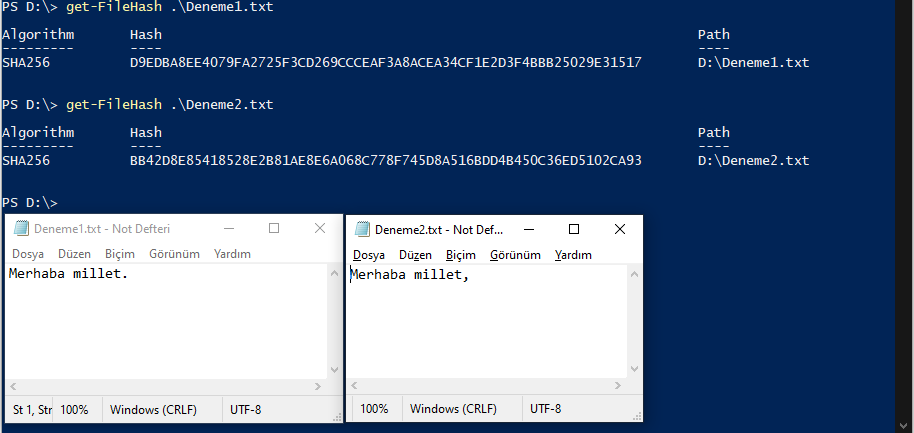
Ör. Aşağıdaki iki dosyadaki sadece son karakter farklı olmasına rağmen, ilgili hash’in nasıl değiştiğini görebilirsiniz.
Peki yazımızın konusu ne 🙂 Farklı “checksum” yöntemleri mi? Ya da yukarıda saydığım MD5 ya da SHA yaklaşımları mı? Aslına bakarsanız hayır. Bunlara ilişkin kaynaklar kısmına bir kaç sayfa koyacağım.
Bu yazımda, basit bir “checksum” hesabını nasıl yapabileceğimize ilişkin bir kod parçasına göz atacağız. Daha sonra bunu daha kısa nasıl yazabiliriz ona bakacağız. Elimizdeki malzeme aşağıdaki gibi:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#include <cstdint> std::uint8_t checksum(const std::uint8_t* p, const std::uint8_t len) { std::uint8_t sum {0U}; for (std::uint8_t i = 0U; i < len; i++){ sum += *p; ++p; }; return sum; } |
Evet, yukarıdaki kod temelde, verilen içeriği byte olarak toplayıp, 255’e bölüp (aslında bölme yok elbette ama 255’i geçince bu şekilde davrandığını düşünebilirsiniz) kalanı, “checksum” olarak dönüyor. Çok basit bir yöntem, güvenilir olmayabilir ama şimdilik yeterli. Peki yukarıdaki kodu nasıl daha kısaltabiliriz? Burada elbette işaretçiler veya benzeri kodlar ile kısaltılabilir ama elimizin altında bulunan bir araç ile bunu çok daha kolay bir şekilde yapabiliriz.
Nedir o araç? std::accumulate. numeric başlık dosyası içerisinde bulunan ve aşağıda örnek bir prototipini görebileceğiniz bu fonksiyon, init‘e, [first, last) arasındaki değerleri de toplayarak döner.
template< class InputIt, class T >
T accumulate( InputIt first, InputIt last, T init );
|
1 2 3 4 5 6 7 |
#include <cstdint> #include <numeric> std::uint8_t checksum(const std::uint8_t* p, const std::uint8_t len) { return std::accumulate(p, p + len, std::uint8_t(0U)); } |
Gördüğünüz üzere kod, çok daha temiz ve bana göre anlaşılabilir oldu.
Bu bağlamda, her fırsatta STL kütüphanelerine göz atmakta fayda var. Bu kütüphaneler, bir çok faydalı kabiliyeti içerisinde barındırıyor. Bunlar genelde (ki büyük bir ihtimal ile çoğunlukla), sizlerin ve benim geliştirebileceğim benzer kabiliyetlerden hem daha hızlı, hem de sağlam olduğunu düşünebilirsiniz. Bir sonraki yazımda görüşmek dileğiyle, sağlıklı günler diliyorum.
Kaynaklar
- https://www.howtogeek.com/363735/what-is-a-checksum-and-why-should-you-care/
- https://www.wikiwand.com/en/MD5
- https://www.wikiwand.com/en/Checksum